VCAI-ASSETS is a hub to access a range of human shape and performance capture assets/libraries from the the Visual Computing and Artificial Intelligence Department , the former Graphics, Vision and Video Group and partner research groups at MPI for Informatics and elsewhere. These assets provide an opportunity to enable further research in different fields such as full body performance capture, facial performance capture, or hand and finger performance capture.
Licence: Please see the individual pages for details on license/restrictions. In general, permission to use the Software is granted only for non-commercial academic purposes. If the software is used, the licensee is required to cite the use of the corresponding publication.

Step2Motion: Locomotion Reconstruction from Pressure Sensing Insoles
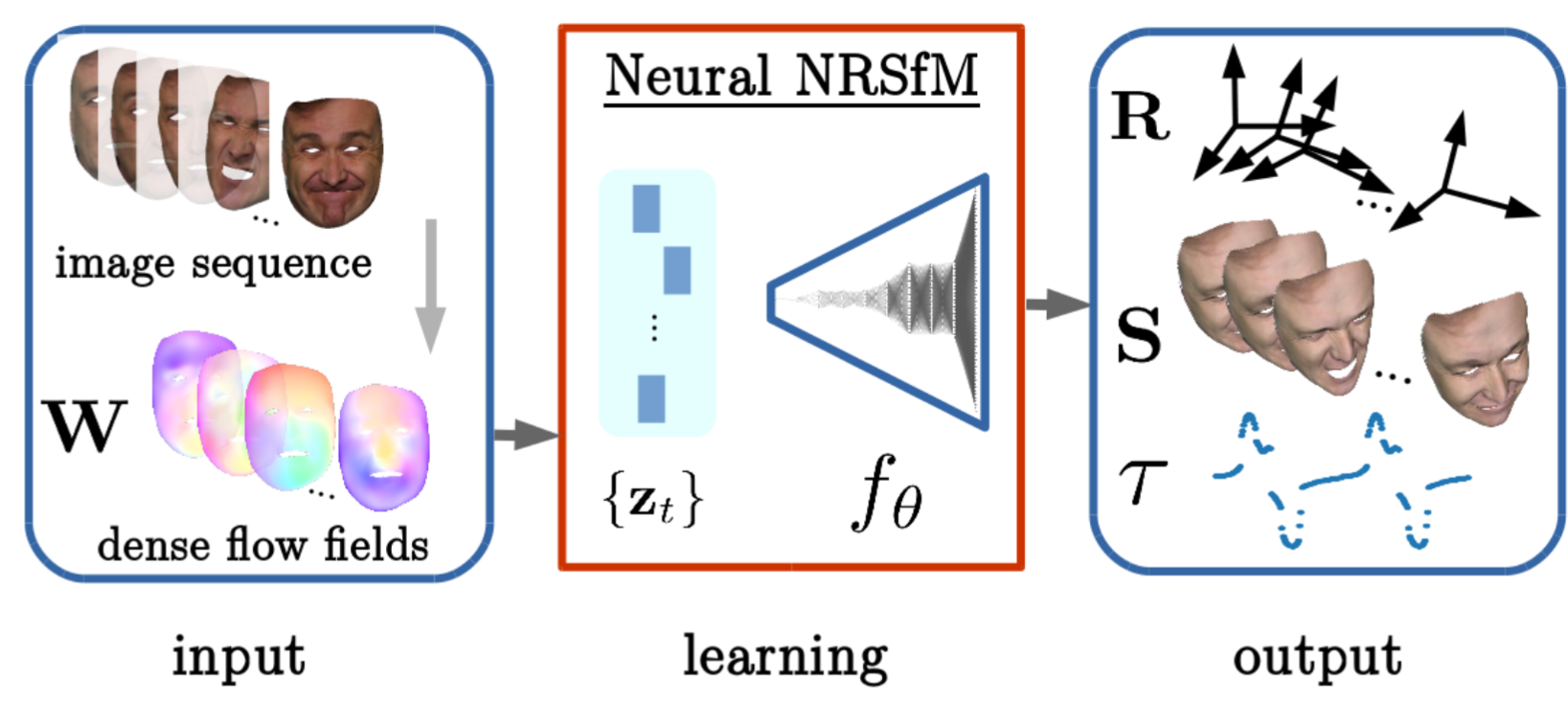
Human motion is fundamentally driven by continuous physical interaction with the environment. Whether walking, running, or simply standing, the forces exchanged between our feet and the ground provide crucial insights for understanding and reconstructing human movement.

GRMM: Real-Time High-Fidelity Gaussian Morphable Head Model with Learned Residuals
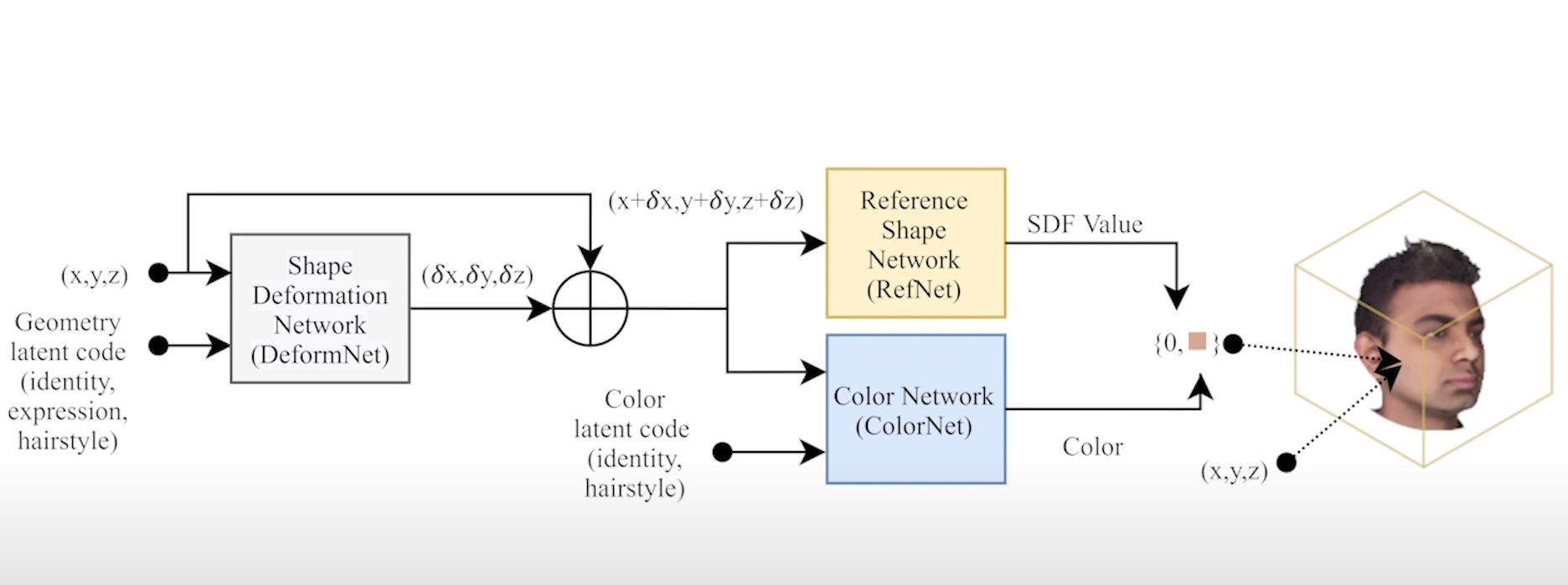
3D Morphable Models (3DMMs) enable controllable facial geometry and expression editing for reconstruction, animation, and AR/VR, but traditional PCA-based mesh models are limited in resolution, detail, and photorealism.

UMA: Ultra-detailed Human Avatars via Multi-level Surface Alignment
UMA introduces a new dataset featuring multi-view 6K video recordings, capturing subjects wearing clothing with challenging texture patterns and rich dynamics. The fidelity of the reconstructed avatars makes them particularly suitable for virtual and mixed reality, where users can closely observe fine-grained appearance details.

Relightable Holoported Characters: Capturing and Relighting Dynamic Human Performance from Sparse Views
We present Relightable Holoported Characters (RHC), a novel person-specific method for free-view rendering and relighting of full-body and highly dynamic humans solely observed from sparse-view RGB videos at inference...

OLATverse: A Large-scale Real-world Object Dataset with Precise Lighting Control
We introduce OLATverse, a large-scale real-world dataset comprising over 9M images of 765 objects, captured from multiple viewpoints under a diverse set of precisely controlled lighting conditions. While recent advances in object-centric inverse rendering, novel view synthesis and relighting have demonstrated promising results, most...
EgoAvatar: Egocentric View-Driven and Photorealistic Full-body Avatars
We first present a character model that is animatible, i.e. can be solely driven by skeletal motion, while being capable of modeling geometry and appearance. Then, we introduce a personalized egocentric motion capture component, which recovers full-body motion from an egocentric video...

Real-time Free-view Human Rendering from Sparse-view RGB Videos using Double Unprojected Textures
We propose Double Unprojected Textures (DUT), a new method to synthesize photoreal 4K novel-view renderings in real-time. Our method consistently beats baseline approaches in terms of rendering quality and inference speed. Moreover, it generalizes to, both, in-distribution (IND) motions, i.e. dancing, and out-of-distribution (OOD) motions, i.e. standing long jump...

TriHuman: A Real-time and Controllable Tri-plane Representation for Detailed Human Geometry and Appearance Synthesis
Creating controllable, photorealistic, and geometrically detailed digital doubles of real humans solely from video data is a key challenge in Computer Graphics and Vision, especially when real-time performance is required. Recent methods attach a neural radiance field (NeRF) to an articulated structure, e.g., a body model...

3DPR: Single Image 3D Portrait Relighting with Generative Priors
Rendering novel, relit views of a human head, given a monocular portrait image as input, is an inherently underconstrained problem. The traditional graphics solution is to explicitly decompose the input image into geometry, material and lighting via differentiable rendering...

HumanOLAT: A Large-Scale Dataset for Full-Body Human Relighting and Novel-View Synthesis
Simultaneous relighting and novel-view rendering of digital human representations is an important yet challenging task with numerous applications. We introduce the HumanOLAT dataset, the first publicly accessible large-scale dataset providing multi-view One-Light-at-A-Time (OLAT) captures of full-body humans...

Relightable Neural Actor with Intrinsic Decomposition and Pose Control
Creating a controllable and relightable digital avatar from multi-view video with fixed illumination is a very challenging problem since humans are highly articulated, creating pose-dependent appearance effects...
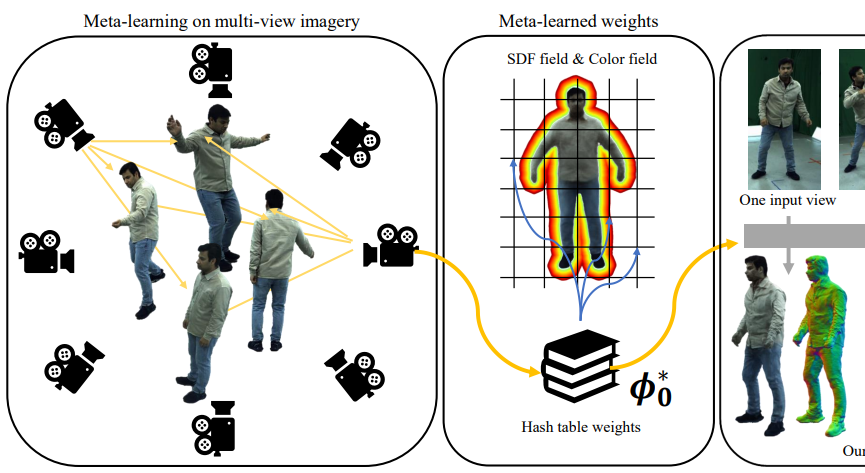
MetaCap: Meta-learning Priors from Multi-View Imagery for Sparse-view Human Performance Capture and Rendering
Faithful human performance capture and free-view render- ing from sparse RGB observations is a long-standing problem in Vision and Graphics. The main challenges are the lack of observations and the inherent ambiguities of the setting...
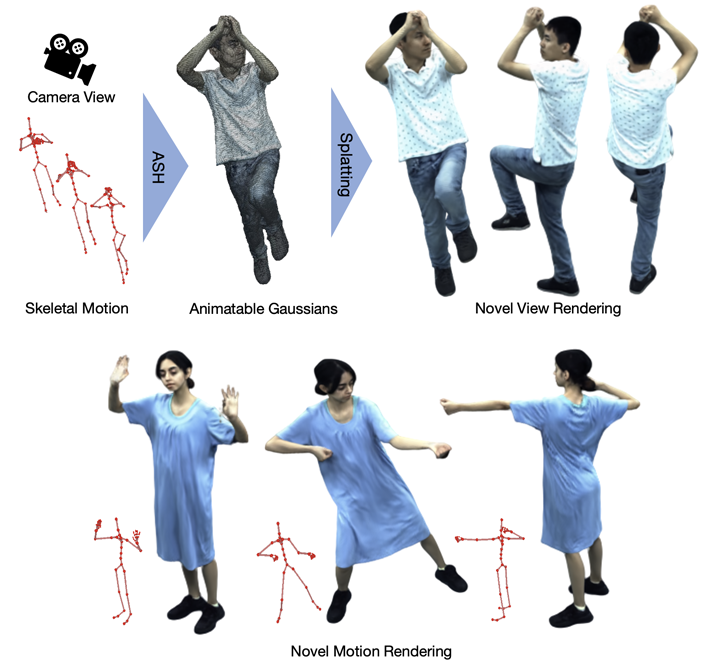
ASH: Animatable Gaussian Splats for Efficient and Photoreal Human Rendering
Real-time rendering of photorealistic and controllable human avatars stands as a cornerstone in Computer Vision and Graphics. While recent advances in neural implicit rendering have unlocked unprecedented photorealism for digital avatars...
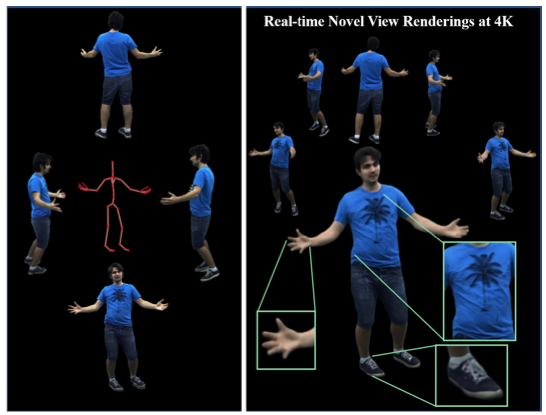
Holoported Characters: Real-time Free-viewpoint Rendering of Humans from Sparse RGB Cameras
We present the first approach to render highly realistic free-viewpoint videos of a human actor in general apparel, from sparse multi-view recording to display, in real-time at an unprecedented 4K resolution...

Neural Actor: Neural Free-view Synthesis of Human Actors with Pose Control
We propose Neural Actor (NA), a new method for high-quality synthesis of humans from arbitrary viewpoints and under arbitrary controllable poses. Our method is built upon recent neural scene representation...

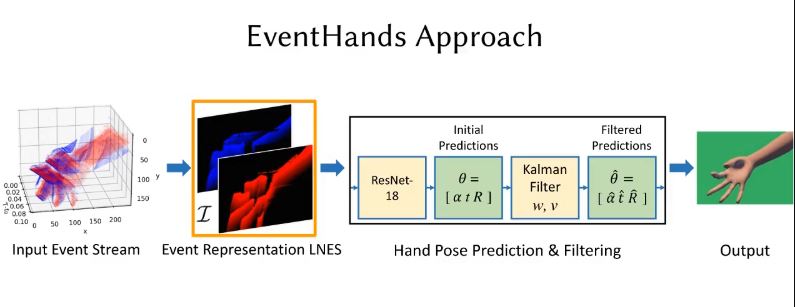
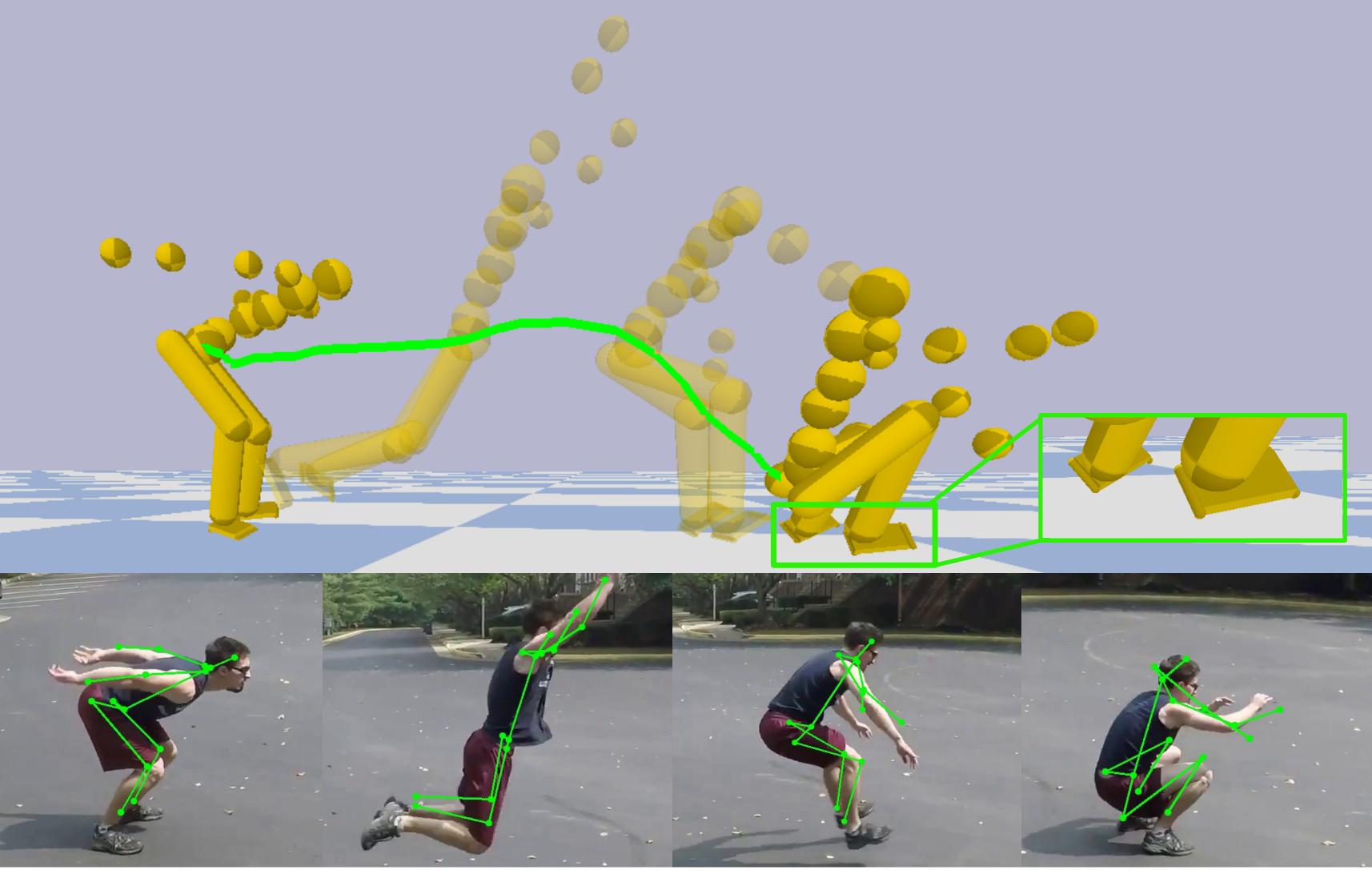

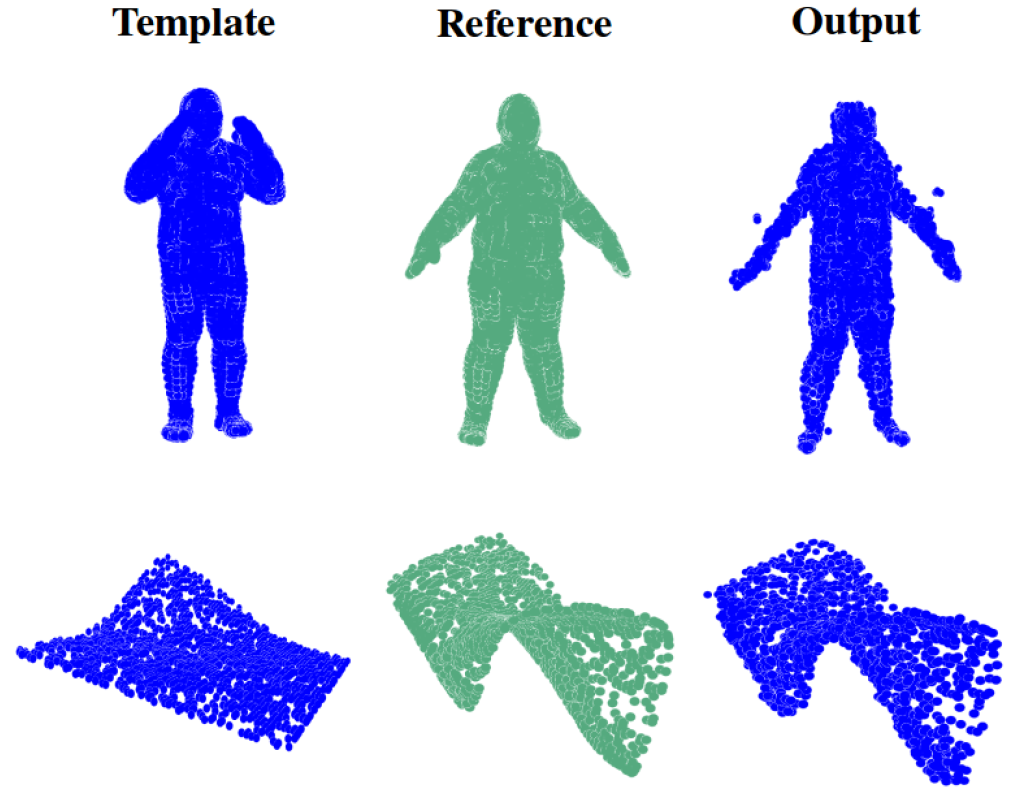
DeepCap: Monocular Human Performance Capture Using Weak Supervision
Human performance capture is a highly important computer vision problem with many applications in movie production and virtual/augmented reality. Many previous performance capture approaches either required expensive multi-view setups...
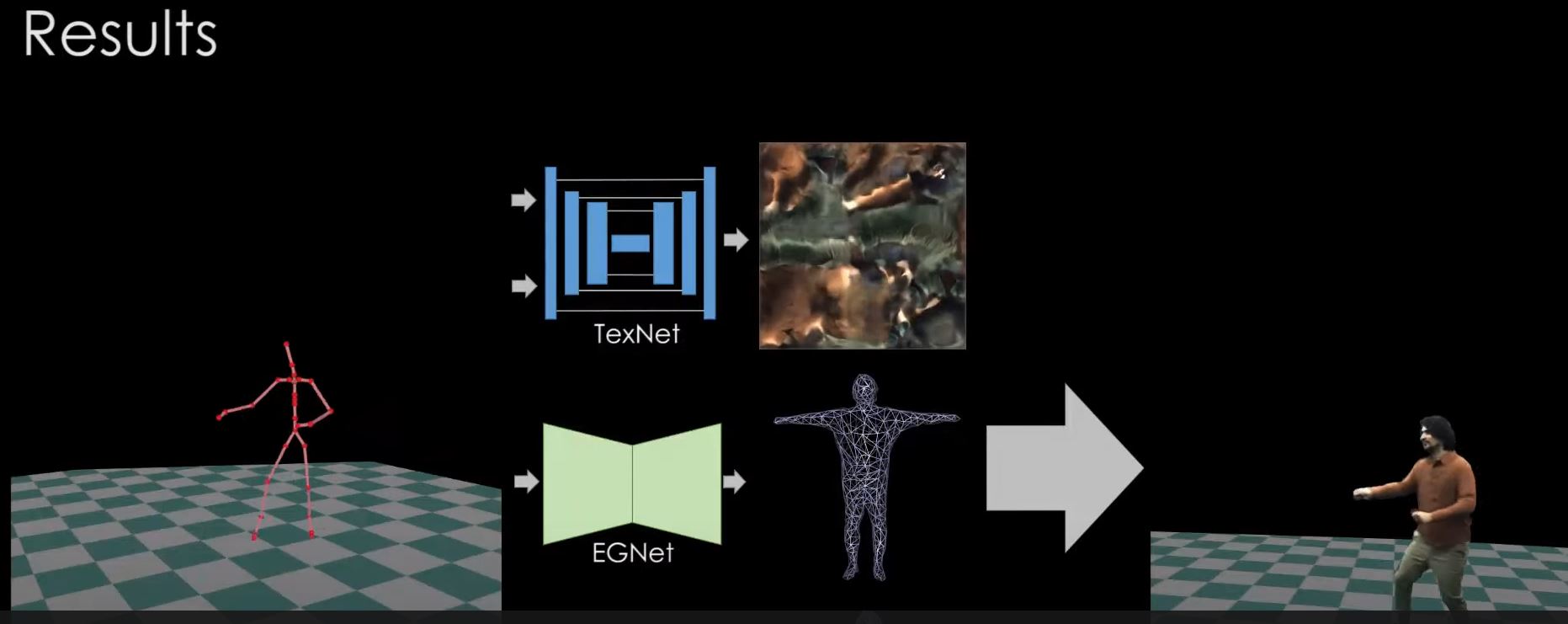


XNect: Real-time Multi-Person 3D Motion Capture with a Single RGB Camera
We present a real-time approach for multi-person 3D motion capture at over 30 fps using a single RGB camera. It operates successfully in generic scenes which may contain occlusions by objects and by other people...